")
")
Sirius 2.0 : Under the Hood
This summer was quite intense for the Sirius team. Sirius 1.0.0 was barely out that development of the 2.0 stream started while report from adopters which are not part of the Eclipse Release train started to appear.
That represents fixing more than 100 tickets since the end of june, a few for Sirius 1.0.1 which got published a few weeks ago (and is part of Luna SR1). From those tickets 82 are targetting Sirius 2.0 (over a current perimeter of 101 tickets), we are currently validating the changes and closing the gap. As a sidenote more than one third of the tickets implemented in this version are directly funded by end users (hint : this might be you).
Sirius 2.0 will be released just before EclipseCon Europe , most of the 21 enhancements in this scope are already implemented and are under validation: now might be a good time for giving a look.
These enhancements are mostly focused on the diagram editor user experience, fixing long standing issues inherited from the default behavior of the GMF runtime and bringing nice features for intensive users of diagrams. But we'll tell more about that in a specific post, lets focus on the "not so visible changes" for now :
We worked on the basis of EcoreTools 2.0 with a "big enough" model to detect such bottlenecks and mostly focused our efforts on the CPU usage (for now but memory will also be important at some point too). 1.5Go heap was the target, as long as the scenario were doing fine within this bound we did not investigate.
What is a "big enough" model you will ask, it is composed of 500 000 model elements (here EClasses, EAttributes, EPackages ...). 20 000 representations are created on top of those, 2 of them representing hundreds of EClasses.
The test data is reverse engineered from the Sirius source code itself which make it quite "close" to a sensible Ecore model. Such a model makes it easy to identify bottlenecks: places where your code have a complexity relative to the number of model elements, or places where you are doing too much work on the UI thread.
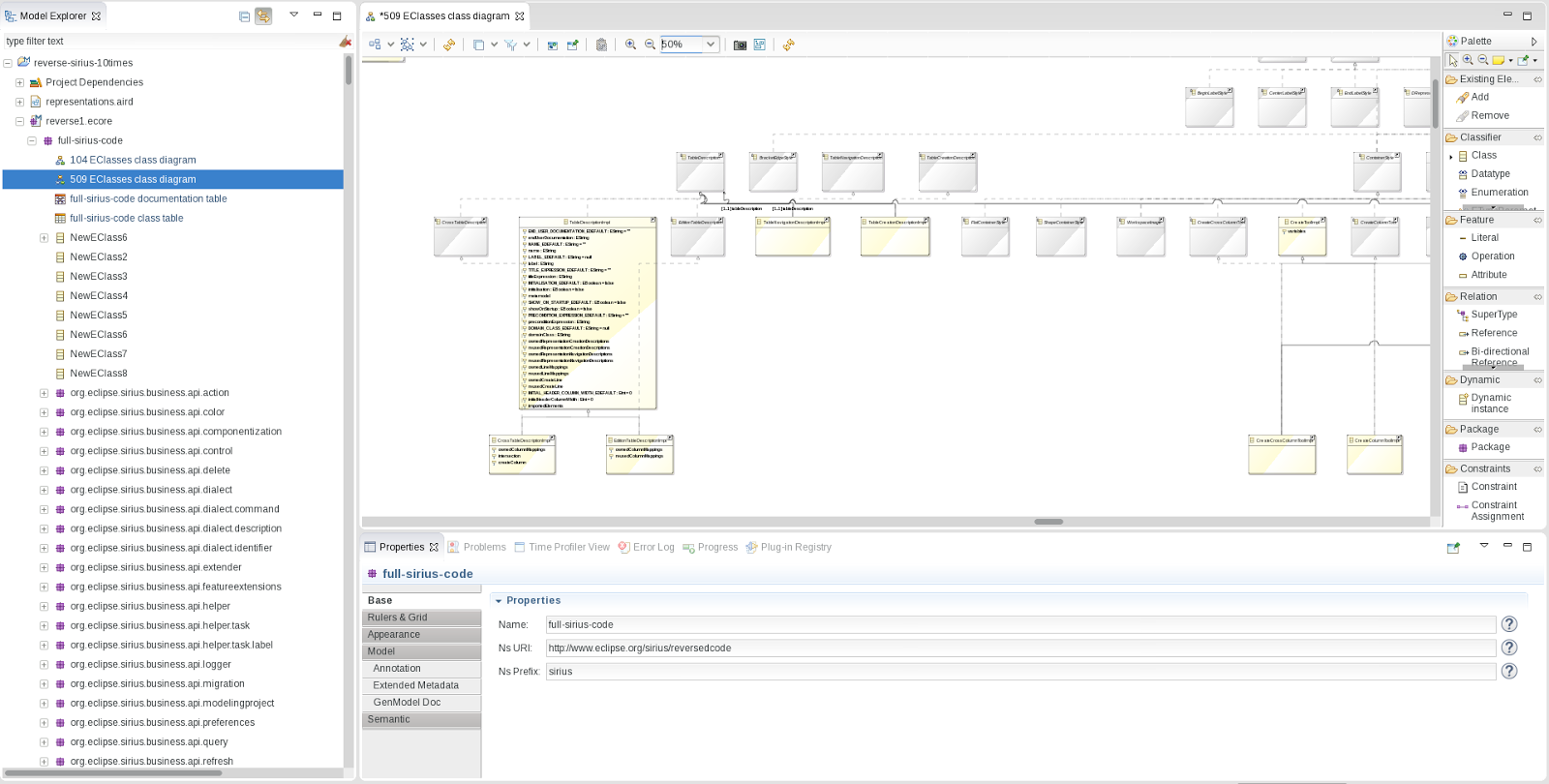
This has proven to be a very efficient way to identify problems and to fix them. Having a consistent installation of EcoreTools + Sirius is quite easy, opening the test project become a breeze then and anybody in the team can reproduce the problem and measure for himself.
And here we are :
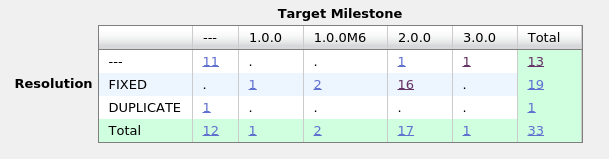
We fixed 16 tickets tagged "performances" for the 2.0 release, here is the list of improvements :
- Sirius is initializing itself quicker (notable on startups and first usage)
- Many calls from the UI threads which were scaling poorly when you have thousands of representations are now way faster
- Delete have seen a big boost and is now scaling based on what you specify and how many things have changed during the execution of your tool independently of the size of the model
- Diagram having lists with many elements are created and refreshed quicker (the improvement is noticeable has soon as you have lists with hundreds of elements)
- Select All used to have an irritable lag when you were working on a big model, it is now instantly completed.
- Tree Editors defined using Sirius are now more efficient in refreshing the SWT Components.
But more things have been identified often with partial patches which have not graduated yet to the stage of "reviewed and regression tested" but will in the next releases. Expect some improvements in the way "save" is handled when you have hundreds of resources. This is a constant effort but one which has great pay-off: any improvement in Sirius itself brings improvements in the dozens of tools which are relying on it.
Performances are always a tricky issue for a generic framework or technology, so many things will depend on how its used and in which context and the most innocent change can dramatically impact the properties of your tool. The #1 rule is : have test data which are representative of what you want to achieve, make sure it can be used and migrated easily from version to version.
Another area which have seen improvements is about using Sirius in "other contexts".
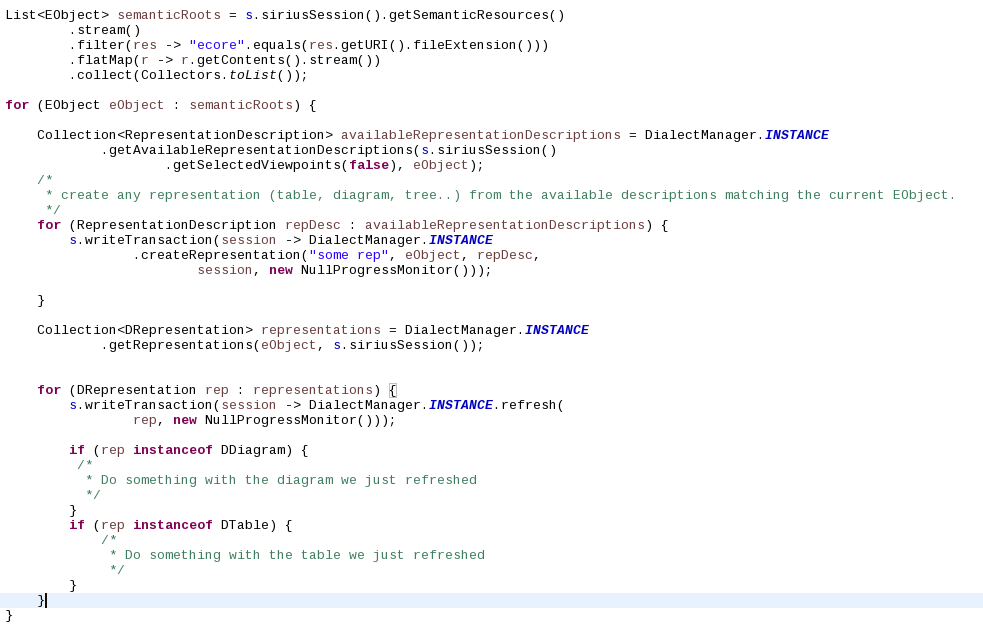
A first batch of changes has been merged so that some of the basic services offered by Sirius are now able to run without any UI. Things like loading a representation resource, creating a diagram, refreshing it, modifying the model and saving can now be used as a server-side or continuous integration process for instance.
Here is a scenario which will work in headless :
I'm pretty excited about this release and I'm looking forward to see these improvements in the tools already adopting Sirius. Of course these are just a few more steps closer to the goal, Sirius 3.0 planned for June will bring even more !
That represents fixing more than 100 tickets since the end of june, a few for Sirius 1.0.1 which got published a few weeks ago (and is part of Luna SR1). From those tickets 82 are targetting Sirius 2.0 (over a current perimeter of 101 tickets), we are currently validating the changes and closing the gap. As a sidenote more than one third of the tickets implemented in this version are directly funded by end users (hint : this might be you).
Sirius 2.0 will be released just before EclipseCon Europe , most of the 21 enhancements in this scope are already implemented and are under validation: now might be a good time for giving a look.
These enhancements are mostly focused on the diagram editor user experience, fixing long standing issues inherited from the default behavior of the GMF runtime and bringing nice features for intensive users of diagrams. But we'll tell more about that in a specific post, lets focus on the "not so visible changes" for now :
Performances and Scalability
Another strong focus of the 2.0 version was performances and scalability : finding bottlenecks and taking them down.We worked on the basis of EcoreTools 2.0 with a "big enough" model to detect such bottlenecks and mostly focused our efforts on the CPU usage (for now but memory will also be important at some point too). 1.5Go heap was the target, as long as the scenario were doing fine within this bound we did not investigate.
What is a "big enough" model you will ask, it is composed of 500 000 model elements (here EClasses, EAttributes, EPackages ...). 20 000 representations are created on top of those, 2 of them representing hundreds of EClasses.
The test data is reverse engineered from the Sirius source code itself which make it quite "close" to a sensible Ecore model. Such a model makes it easy to identify bottlenecks: places where your code have a complexity relative to the number of model elements, or places where you are doing too much work on the UI thread.
This has proven to be a very efficient way to identify problems and to fix them. Having a consistent installation of EcoreTools + Sirius is quite easy, opening the test project become a breeze then and anybody in the team can reproduce the problem and measure for himself.
And here we are :
We fixed 16 tickets tagged "performances" for the 2.0 release, here is the list of improvements :
- Sirius is initializing itself quicker (notable on startups and first usage)
- Many calls from the UI threads which were scaling poorly when you have thousands of representations are now way faster
- Delete have seen a big boost and is now scaling based on what you specify and how many things have changed during the execution of your tool independently of the size of the model
- Diagram having lists with many elements are created and refreshed quicker (the improvement is noticeable has soon as you have lists with hundreds of elements)
- Select All used to have an irritable lag when you were working on a big model, it is now instantly completed.
- Tree Editors defined using Sirius are now more efficient in refreshing the SWT Components.
But more things have been identified often with partial patches which have not graduated yet to the stage of "reviewed and regression tested" but will in the next releases. Expect some improvements in the way "save" is handled when you have hundreds of resources. This is a constant effort but one which has great pay-off: any improvement in Sirius itself brings improvements in the dozens of tools which are relying on it.
Performances are always a tricky issue for a generic framework or technology, so many things will depend on how its used and in which context and the most innocent change can dramatically impact the properties of your tool. The #1 rule is : have test data which are representative of what you want to achieve, make sure it can be used and migrated easily from version to version.
Headless - aka reuse the plugins with no UI
Another area which have seen improvements is about using Sirius in "other contexts".
A first batch of changes has been merged so that some of the basic services offered by Sirius are now able to run without any UI. Things like loading a representation resource, creating a diagram, refreshing it, modifying the model and saving can now be used as a server-side or continuous integration process for instance.
Here is a scenario which will work in headless :
I'm pretty excited about this release and I'm looking forward to see these improvements in the tools already adopting Sirius. Of course these are just a few more steps closer to the goal, Sirius 3.0 planned for June will bring even more !
Sirius 2.0 : Under the Hood was originally published by Cédric Brun at CTO @ Obeo on October 16, 2014.
Auteur d'origine: Cédric Brun