")
")
EMF Compare - giant steps towards a working merger
EMF Compare, or how to provide meaningful comparison algorithms and visualization for models. Comparing the models' XMI serializations as text is a chore that we should never have to go back to, and EMF Compare has always strived at doing the best possible job towards that end.
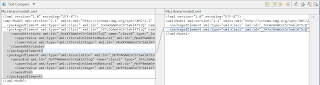
Who would rather compare their models textually :
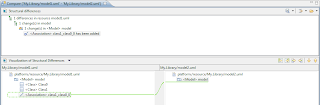
Than compare them logically (yes, these are the same models as above) :
However, EMF Compare still had issues with most algorithm : small errors when matching elements together, differences that weren't detected ... and worst of all : merging all diffs from one side to the other rarely gave the expected result of "two identical models", i.e : if the comparison process in itself was working fairly well, we had a huge number of failures when merging.
We've decided to tackle this problem the way we should have from the very start : list all potential differences that can be observed between two models ... and create the corresponding unit test!
The results are already showing. True, we are still missing a number of unit tests in order to test all potential use cases we can list ... but we've already fixed an incredible number of bugs be they known (half of our opened bugs, forty-ish out of eighty or so) or bugs we had never detected before. The number of unit tests talks for itself :
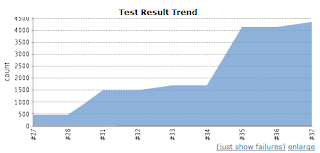
That's 4000 unit tests and as many different combinations of differences added and fixed in the past weeks.
I won't lie, some of these tests are redundant because of the way we decided to work : we are not trying to cover code, but rather cover use cases; which means some of these tests overlap with others. This does mean, however, that we are fairly sure we'll never have regressions on things that are tested :).
And now, back to the last few tests we are still missing!
Who would rather compare their models textually :

Than compare them logically (yes, these are the same models as above) :

However, EMF Compare still had issues with most algorithm : small errors when matching elements together, differences that weren't detected ... and worst of all : merging all diffs from one side to the other rarely gave the expected result of "two identical models", i.e : if the comparison process in itself was working fairly well, we had a huge number of failures when merging.
We've decided to tackle this problem the way we should have from the very start : list all potential differences that can be observed between two models ... and create the corresponding unit test!
The results are already showing. True, we are still missing a number of unit tests in order to test all potential use cases we can list ... but we've already fixed an incredible number of bugs be they known (half of our opened bugs, forty-ish out of eighty or so) or bugs we had never detected before. The number of unit tests talks for itself :

That's 4000 unit tests and as many different combinations of differences added and fixed in the past weeks.
I won't lie, some of these tests are redundant because of the way we decided to work : we are not trying to cover code, but rather cover use cases; which means some of these tests overlap with others. This does mean, however, that we are fairly sure we'll never have regressions on things that are tested :).
And now, back to the last few tests we are still missing!
Auteur d'origine: Laurent